Tag: Semantic Search
-

Conversation about Semantic SEO
Everything started with my thoughts on a article written by Damian Thompson and called What The Heck Is Semantic SEO & Should You Care At All? At the end of the day it doesn’t matter whether you call it Semantic SEO or just SEO. Adapting to the semantic search topography will be part of every SEO’s job description going…
-

The Power of Google Translate
Google Translate is an incredibly powerful tool that has transformed the way people communicate and access information across the globe. With its powerful translation capabilities, Google Translate has bridged the language barrier and made it possible for people to communicate with each other without the need for a common language. However, Google Translate has recently added…
-

2015 SEO Predictions
Semantic Search is changing SEO forever. It’s all about optimising your content and everything you do online for your customers rather than just Google, and this is a radical shift in thinking. SEO 2015 Workout: How To Gain Weight from SEMrush Google wants us to be more human. Words like trust, authority, personality are fashionable…
-
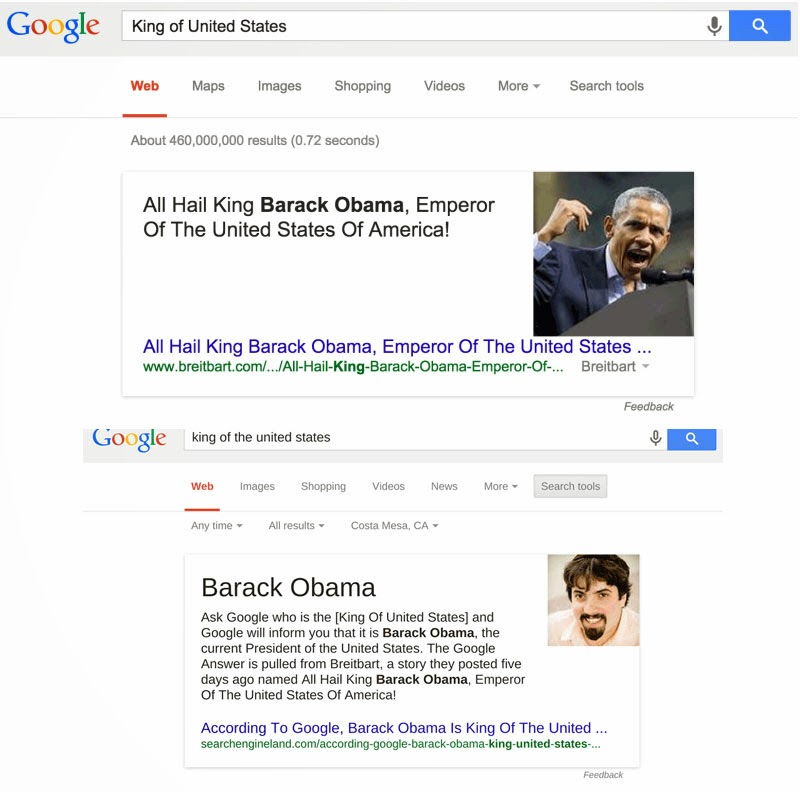
When Obama & +Barry Schwartz Became King Of The United States For The Day
Conversation with David Amerland and Peter Hatherley “Why would Google show this answer when it is clearly wrong? Is it an Easter Egg? I strongly doubt it. But it does look to be a case where Google got it wrong when it comes to getting answers from third party sources.” – Barry Schwartz Peter Hatherley: Still semantically relevant…
-

Topic Modelling and Semantic Connectivity in SEO
Topic Modelling & Semantic Connectivity By Rand Fishkin . Search engine optimisation (SEO) is an important part of digital marketing, aimed at improving the online visibility and ranking of websites in search engine results pages (SERPs). Over the years, SEO has evolved significantly, driven by the need to provide more relevant and useful information to searchers…
-

Data Density and Semantic Search – Hangout On Air with David Amerland and Mark Traphagen
What is Semantic Search? Semantic search is an advanced search technique that uses machine learning algorithms to understand the intent of the user’s search query and provide more relevant results in the search result pages (SERPs). How Semantic Search Works The technology is designed to improve the accuracy and precision of search results by analysing the meaning…