Conversation about Semantic SEO
Everything started with my thoughts on a article written by Damian Thompson and called What The Heck Is Semantic SEO & Should You Care…
Everything started with my thoughts on a article written by Damian Thompson and called What The Heck Is Semantic SEO & Should You Care…
Google Translate is an incredibly powerful tool that has transformed the way people communicate and access information across the globe. With its powerful…
Semantic Search is changing SEO forever. It’s all about optimising your content and everything you do online for your customers rather than…
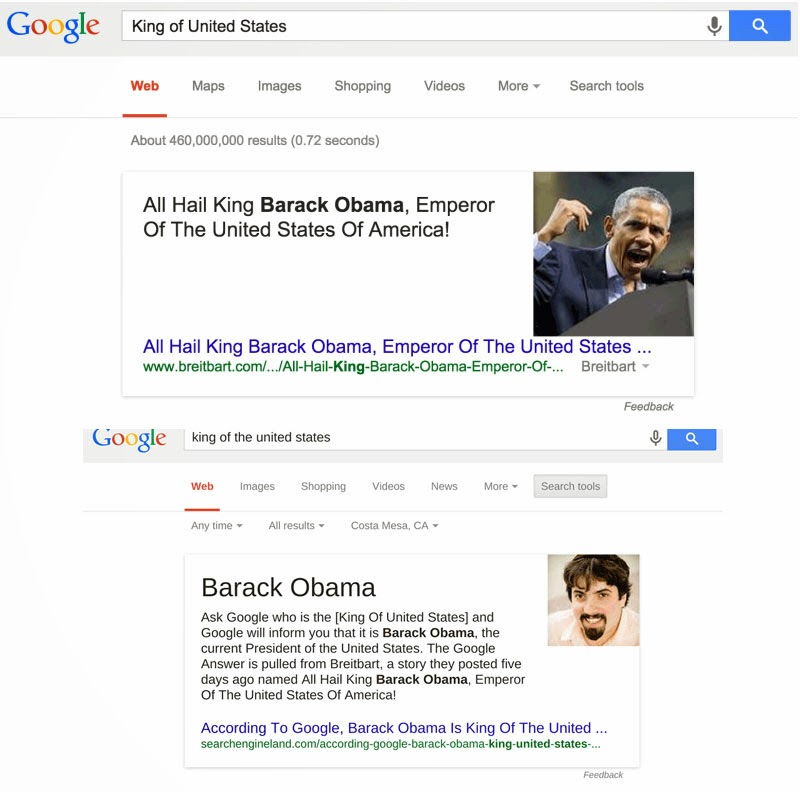
Conversation with David Amerland and Peter Hatherley “Why would Google show this answer when it is clearly wrong? Is it an Easter Egg? I strongly…
Topic Modelling & Semantic Connectivity By Rand Fishkin . Search engine optimisation (SEO) is an important part of digital marketing, aimed at improving…
What is Semantic Search? Semantic search is an advanced search technique that uses machine learning algorithms to understand the intent of the user’s search…